텍스트 마이닝 과정
- 머신러닝 기법 : LDA(토픽 모델링 기법), SVM(문서 분류 기법) 등
- 딥러닝 기법 : RNN, LSTM, Transformer, BERT 등
워드 임베딩은 딥러닝 기법에서 입력값으로 쓰임
워드 임베딩?

- 단어를 컴퓨터가 이해할 수 있는 벡터로 표현하는 방법 (단어의 차원을 저차원으로 바꿔줌)
- Word Embedding = Word + Embedding
- Sparse Representation (BOW, TF-IDF)
- Dense Representation (word2vec, Glove 등)
희소 표현(Sparse Representation)의 문제점
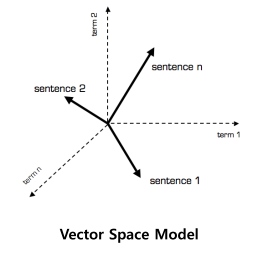
- 문서 데이터에 존재하는 모든 유니크한 단어 수가 벡터의 차원이 되어 고차원 공간이 됨
- 단어의 문맥 정보가 사라짐, 예) 문장 내 순서(word order), 문장 내 동시등장(co-occurrence), (apple(사과) tree, apple(회사) iphone)
- 차원의 저주(Curse of dimensionality)로 인해 분석 기법의 성능이 악화됨
밀집 표현(Dense Representation)

- 이미지나 오디오 데이터는 양질의 고차원 데이터로 표현됨 (dense representation)
- 기존 방법인 VSM은 단어를 discrete symbol로 표시하기 때문에 정보 전달력이 떨어짐
- 기존의 count-based method가 아닌 predictive model을 사용하여 단어의 주변 정보를 반영한 dense presentation을 표현함
워드 임베딩 역사
NPLM → word2vec → fastText → ELMo
NPLM
- Neural Probabilistic Language Model
- 처음으로 제안된 dense representation model
- Neural Network를 이용하여 주변 단어의 단어 등장 확률을 예측함
word2vec
- Skip-Gram with Negative Sampling
- NPLM에서 높은 계산량을 요규하는 문제점을 획기적으로 해결
- 본격적인 word embedding 시대 개막
fastText
- Subword SGNS
- Word2vec에서의 OOV(Out-of-Vocabulary) 문제를 해결
- 학습 단위가 subword로 변경
ELMo
- Embeddings from Language Model
- Bi-directional Language Model을 제안하여 문맥을 반영한 워드 임베딩 기법 제시
- NLP에서 transfer learning이 확산됨
워드 임베딩 공간의 특징

- 단어 관계는 vector 연산
- 비슷한 의미를 가지는 단어들이 군집을 형성
'PROJECT > 텍스트 마이닝을 활용하여 문자 대화내용 분석' 카테고리의 다른 글
| 네이버 기사 크롤러 만들기 (0) | 2023.03.22 |
|---|---|
| 네이버 오픈 API 등록 (0) | 2023.03.20 |
| 텍스트 마이닝 - 텍스트 시각화 (0) | 2023.03.18 |
| 텍스트 마이닝 - 텍스트 분석 (0) | 2023.03.18 |
| 텍스트 마이닝 - 텍스트 가공 (0) | 2023.03.15 |