반응형
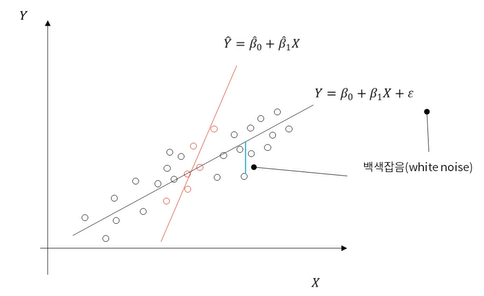
선형 회귀분석(Linear Regression)
- 독립변수와 종속변수가 선형적인 관계가 있다라는 가정하에 분석
- 직선을 통해 종속변수를 예측하기 때문에 독립변수의 중요도와 영향력을 파악하기 쉬움
의사결정나무(Decision Tree)
- 독립 변수의 조건에 따라 종속변수를 분리 (비가 내린다 -> 축구를 하지 않는다)
- 이해하기 쉬우나 overfitting이 잘 일어남
- 오버피팅(overfitting): 과적합, 훈련데이터에 너무 잘 맞아서 훈련데이터를 통한 정확도는 높으나, 테스트데이터에서 정확도가 낮게 나오는 현상
KNN(K-Nearest-Neighbor)
- 새로 들어온 데이터의 주변 k개의 데이터의 class로 분류하는 기법
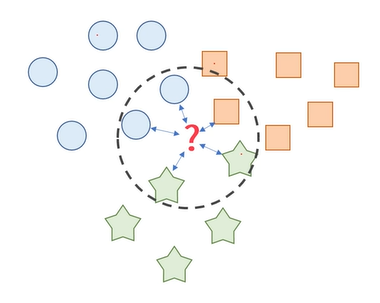
- k는 사람이 지정, 사람이 지정해 줘야하는 것 -> 하이퍼파라미터
Neural Network
- 입력, 은닉, 출력츨으로 구성된 모형으로서 각 층을 연결하는 노드의 가중치를 업데이트하면서 학습
- 최근에 잘 안쓰임

SVM(Support Vector Machine)
- Class 간의 거리(margin)가 최대로 되도록 decision boundary를 만드는 방법
- 학습시간 오래걸림
- 최근에 잘 안쓰임
Ensemble Learning
- 여러 개의 모델(classifier or base learner)을 결합하여 사용하는 모델
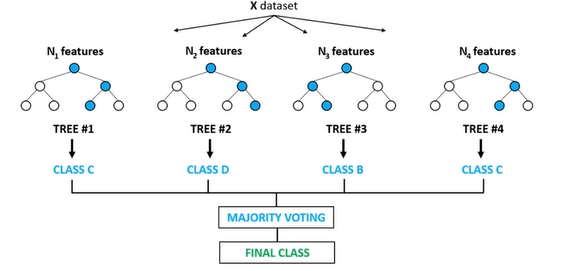
- 데이터가 입력되었을 때, 여러개의 모델을 사용하고, 투표를 통해 최종 분류를 함.
- 좋고 다른 대회에서 자주 사용함, 앙상블 모델이 대부분 유리하게 나옴.
K-means clustering
- Label 없이 데이터의 군집으로 k개로 생성
- 비지도 학습의 대표적인 모델

- 랜덤하게 점을 찍고, 주변에 가까운 곳을 할당
- 단점: k에 따라 성능이 달라짐, 데이터가 고차원으로 갈수록 안맞는 모델
반응형
'머신러닝 > 기초' 카테고리의 다른 글
| 기업이 데이터 분석하는 과정 (0) | 2023.06.28 |
|---|---|
| 모형의 적합성 평가 및 실험설계 (0) | 2022.03.20 |
| 지도학습과 비지도학습 (0) | 2021.12.19 |
| 머신러닝의 개념 (0) | 2021.12.19 |